Platformy PaaS jako narzędzie do szybkiego prototypowania – cz. 8: zarządzanie infrastrukturą z poziomu GitLab
Seria: Platformy PaaS jako narzędzie do szybkiego prototypowania
- Platformy PaaS jako narzędzie do szybkiego prototypowania – cz. 1: Heroku
- Platformy PaaS jako narzędzie do szybkiego prototypowania – cz. 2: Heroku cd.
- Platformy PaaS jako narzędzie do szybkiego prototypowania – cz. 3: Azure App Service
- Platformy PaaS jako narzędzie do szybkiego prototypowania – cz. 4: Azure App Service cd.
- Platformy PaaS jako narzędzie do szybkiego prototypowania – cz. 5: PostgreSQL for Azure
- Platformy PaaS jako narzędzie do szybkiego prototypowania – cz. 6: Terraform
- Platformy PaaS jako narzędzie do szybkiego prototypowania – cz. 7: Terraform i zarządzanie stanem przez Azure Storage
- Platformy PaaS jako narzędzie do szybkiego prototypowania – cz. 8: zarządzanie infrastrukturą z poziomu GitLab ← jesteś tutaj
W poprzednich częściach pokazaliśmy jak możemy w naszej prototypowanej aplikacji szybko zbudować pełny pipeline CI/CD. Następnie udało nam się przeprowadzić deployment na chmurach Heroku i Azure, oraz cały kod przedstawić w postaci Terraformowego skryptu o stanie współdzielonym w zewnętrznym magazynie. Moglibyśmy teraz ruszyć o krok dalej, pozwalając naszemu repozytorium nie tylko zarządzać kodem, ale też dbać o aplikowanie zmian w chmurze.
W celu użycia nie-personalnego konta i posiadania pewnej kontroli nad tworzoną aplikacją powinniśmy utworzyć dedykowaną jednostkę usługi (Service Principal). Na potrzeby artykułu możemy traktować ją jako rodzaj niespersonalizowanej tożsamości.
% az ad sp create-for-rbac --role="Contributor" --scopes="/subscriptions/{SubscribtionID}"
Creating a role assignment under the scope of "/subscriptions/<SubscriptionID>"
Retrying role assignment creation: 1/36
{
"appId": "<UUID>",
"displayName": "azure-cli-2020-11-29-13-22-27",
"name": "http://azure-cli-2020-11-29-13-22-27",
"password": "<PASSWORD>",
"tenant": "<UUID>"
}
Przypisanie jednostce usługi roli „Contributor” pozwoli jej na zarządzanie dostępem do zasobów, a jednocześnie uniemożliwi zmianę w ustawieniach ról AzureRBAC i nadawanie nowych uprawnień.
Następnie możemy przygotować zarys Pipeline’u (.gitlab-ci.yml), którego ogólna idea pozwoli na przygotowanie i przetestowanie zmian w infrastrukturze naszego projektu.
image:
name: hashicorp/terraform:0.13.5
before_script:
- rm -rf .terraform
- terraform --version
- terraform init
stages:
- validate
- plan
- apply
validate:
stage: validate
script:
- terraform validate
plan:
stage: plan
script:
- terraform plan
dependencies:
- validate
apply:
stage: apply
script:
- terraform apply -input=false
only:
- master
dependencies:
- plan
Pierwsze etapy pozwolą na weryfikację i wywołanie planowania zmian, aplikacja nastąpi dopiero na pipeline master. Jako, że będziemy działali w ramach automatycznego zadania, musimy wyłączyć tryb interaktywny poprzez dodanie parametru (-input=false). Dodatkowo powinniśmy uzupełnić wszystkie zmienne środowiskowe wymagane przez aplikację.
Zatem począwszy od zmiennych aplikacyjnych TF_VARS_* możemy rozpocząć przygotowywanie naszych sekretów. Po raz kolejny chciałbym zwrócić uwagę, że wciąż nie zaadresowaliśmy wielu problemów związanych z bezpieczeństwem, a jedynie skupiamy na się na poprawie automatyzacji tworzenia infrastruktury.
Przy próbie wywołania zadania planowania nawet po ustawieniu zmiennych, możemy zobaczyć następujący błąd:
Error: Error building AzureRM Client: Azure CLI Authorization Profile was not found. Please ensure the Azure CLI is installed and then log-in with `az login`.
Nadszedł czas na wykorzystanie uprzednio przygotowanego Service Principal. Provider Azure wymaga pięciu zmiennych:
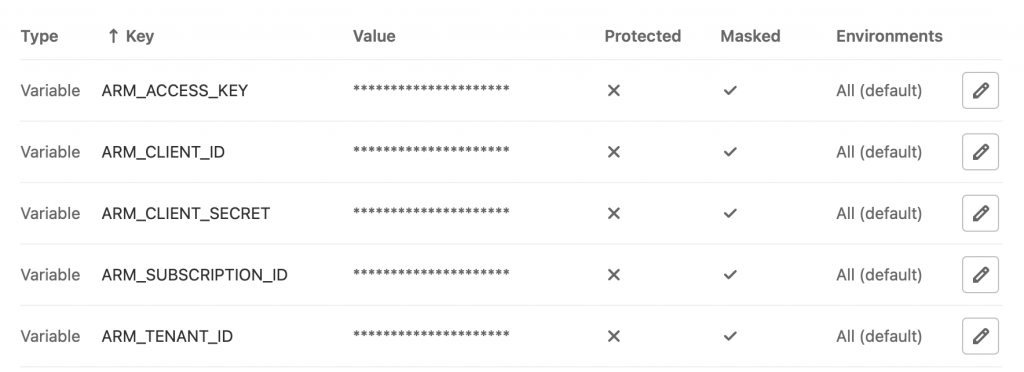 Zasadniczo wszystkie poza id naszej subskrybcji i ACCESS_KEY znanym z poprzedniego artykułu można pozyskać po utworzeniu roli. ARM_CLIENT_ID to tak naprawdę appId, a ARM_CLIENT_SECRET to otrzymane w odpowiedzi hasło.
Zasadniczo wszystkie poza id naszej subskrybcji i ACCESS_KEY znanym z poprzedniego artykułu można pozyskać po utworzeniu roli. ARM_CLIENT_ID to tak naprawdę appId, a ARM_CLIENT_SECRET to otrzymane w odpowiedzi hasło.
Gdy zaaplikujemy wszystkie wspomniane zmiany – nasz Pipeline powinien się zazielenić 🙂
Podsumowanie
Czas chyba odpowiedzieć sobie na dwa pytania. Czy tak naszpikowany zmiennymi pipeline może być w ogóle zarządzalny? Czy to w ogóle bezpieczne?
Cóż – na pewno zmienne aplikacyjne nie powinny być ręcznie konfigurowane poprzez Gitlab’a i być tam przechowywanymi. Powinniśmy korzystać z bezpiecznego składowiska typu Vault i z niego na żądanie pobierać wartości.
Co do ogólnego bezpieczeństwa… Zadania na publicznym GitLab uruchamiane są w Dockerze i nie współdzielą stanu pomiędzy wywołaniami. Pozwalamy jednak zewnętrznemu dostawcy na trzymanie danych naszej jednostki usługi. W planie darmowym, niewiele jest sposobów na obejście tej wady, a więc musielibyśmy posłużyć się integracją z Vault. Wszystko zależy od rozmiaru projektu i naszej determinacji w celu zabezpieczenia go.